Positions and Influence#
Readings#
Scott, J. (2017). Social network analysis (4th edition) (Ch. 6). SAGE Publications.
Borgatti, S. P. (2005). Centrality and network flow. Social Networks, 27(1), 55–71. https://doi.org/10.1016/j.socnet.2004.11.008
Russo, T. C., & Koesten, J. (2005). Prestige, centrality, and learning: A social network analysis of an online class. Communication Education, 54(3), 254–261. https://doi.org/10.1080/03634520500356394
In this part, you’ll explore ways of measuring the importance or centrality of a node in a network, using measures such as Degree, Closeness, and Betweenness centrality, and Page Rank. You’ll learn about the assumptions each measure makes, the algorithms we can use to compute them, and the different functions available on NetworkX to measure centrality.
Node Importance#
Social network analysis is usually interested in answering this question: Based on the structure of the network, which are the most important nodes?
SNA offers different ways of thinking about “importance”.
Let’s load the Karate Club network from NetworkX to explore different measures of node importance.
import networkx as nx
import matplotlib.pyplot as plt
# G = nx.karate_club_graph()
G = nx.krackhardt_kite_graph()
nx.draw_networkx(G)
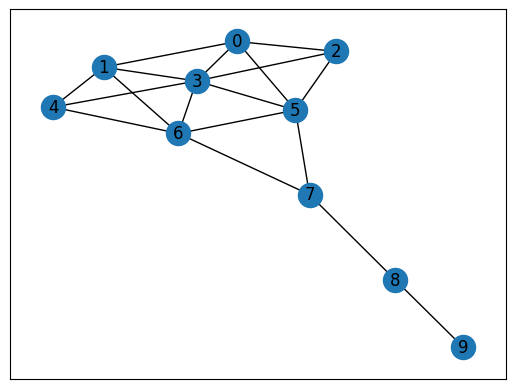
Centrality#
Centrality measures identify the most important nodes in a network:
Influential nodes in a social network
Nodes that disseminate information to many nodes or prevent epidemics
Hubs in a transportation network
Important pages on the Web
Nodes that prevent the network from breaking up
Degree centrality#
Assumption: important nodes have many connections.
Degree: number of neighbors.
Undirected networks: use degree
Directed networks: use in-degree or out-degree
Degree centrality: controls for the size of the network

nx.degree(G)
DegreeView({0: 4, 1: 4, 2: 3, 3: 6, 4: 3, 5: 5, 6: 5, 7: 3, 8: 2, 9: 1})
The degree centrality of node 0 would be: 16 / (34-1) = 0.48
A faster way to calculate degree centrality of all nodes is to use the degree_centrality function:
degree_cen = nx.degree_centrality(G)
degree_cen[0]
0.4444444444444444
For directed networks, in-degree and out-degree are differentiated.
Use in_degree_centrality and out_degree_centrality instead.
Closeness Centrality#
Assumption: important nodes are close to other nodes.
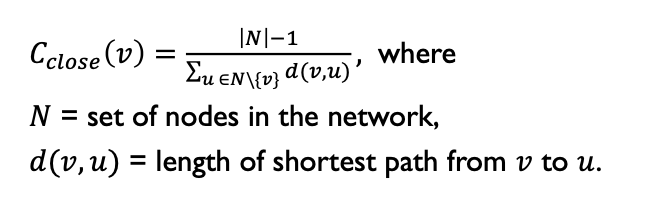
close_cen = nx.closeness_centrality(G)
close_cen[0]
0.5294117647058824
sum(nx.shortest_path_length(G, 0).values())
17
(len(G.nodes())-1) / sum(nx.shortest_path_length(G, 0).values())
0.5294117647058824
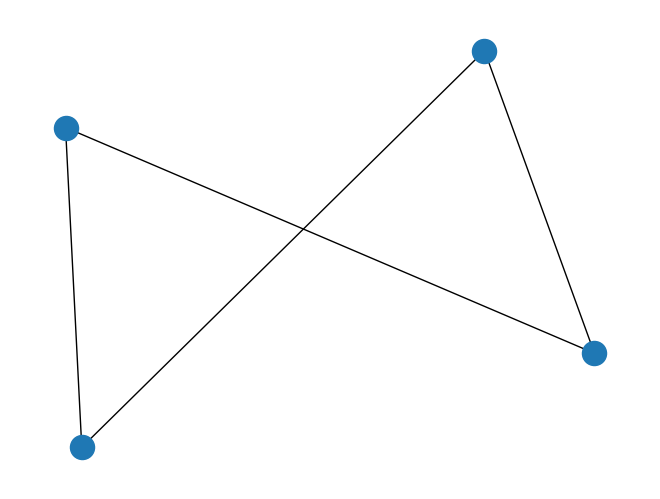
In a triangle, the closeness centrality of each node is 1, because each node is one hop away from the other two nodes.
In a square, the closeness centrality of each node is 0.75, because each node is one hop away from two other nodes and two hops away from the fourth node. The closeness centrality = (4 - 1) / (1 + 1 + 2) = 3/4.
square = nx.cycle_graph(4)
nx.draw_spring(square)
print(nx.closeness_centrality(square))
{0: 0.75, 1: 0.75, 2: 0.75, 3: 0.75}
Betweenness Centrality#
Assumption: important nodes connect other nodes.
Betweeness centrality for node N is computed as:
The percent of cases where
For each pair of nodes M and P (which are not N)
The shortest path from M to P passes through N
Normalization: betwenness centrality values will be larger in graphs with many nodes. To control for this, we divide centrality values by the number of pairs of nodes in the graph (excluding the considered node).
btwn_cen = nx.betweenness_centrality(G, normalized = True)
btwn_cen[0]
0.023148148148148143
We can identify the top 5 nodes with the highest betweenness centrality:
import operator
sorted(btwn_cen.items(), key=operator.itemgetter(1), reverse = True)[0:5]
[(7, 0.38888888888888884),
(5, 0.23148148148148148),
(6, 0.23148148148148148),
(8, 0.2222222222222222),
(3, 0.10185185185185183)]
Eigenvector Centrality#
Complex math, but assigns centrality to nodes through recursive process where
More and stronger connections are positive
Connections to nodes with higher eigenvector centrality contribute more than connections to nodes with lower eigenvector centrality
A key part of the original PageRank in Google
eigen_cen = nx.eigenvector_centrality(G)
sorted(eigen_cen.items(), key=operator.itemgetter(1), reverse = True)[0:5]
[(3, 0.48102048812210046),
(5, 0.3976910106255469),
(6, 0.3976910106255469),
(0, 0.35220898139203594),
(1, 0.35220898139203594)]
Here, we see node 33 has higher eigenvector centrality than node 0, which has higher betweenness centrality. One reason is node 0 is connected to a bunch of nodes that are not as “central” as nodes connected with node 33.
Extract Node-level Features from the Network#
These centality measures can be meaningful for different purposes.
They can be used as features for other analyses.
It is trivial to compute a range of node-level features and put them in a data frame.
import pandas as pd
df = pd.DataFrame(index = G.nodes)
df['club'] = pd.Series(nx.get_node_attributes(G, 'club')) # extract node attribute 'club' in the network
df['degree'] = pd.Series(nx.degree(G))
df['degree_centrality'] = pd.Series(nx.degree_centrality(G))
df['closeness_centrality'] = pd.Series(nx.closeness_centrality(G))
df['betweenness_centrality'] = pd.Series(nx.betweenness_centrality(G, normalized = True))
df['eigenvector_centrality'] = pd.Series(nx.eigenvector_centrality(G))
df
| club | degree | degree_centrality | closeness_centrality | betweenness_centrality | eigenvector_centrality | |
|---|---|---|---|---|---|---|
| 0 | NaN | (0, 4) | 0.444444 | 0.529412 | 0.023148 | 0.352209 |
| 1 | NaN | (1, 4) | 0.444444 | 0.529412 | 0.023148 | 0.352209 |
| 2 | NaN | (2, 3) | 0.333333 | 0.500000 | 0.000000 | 0.285835 |
| 3 | NaN | (3, 6) | 0.666667 | 0.600000 | 0.101852 | 0.481020 |
| 4 | NaN | (4, 3) | 0.333333 | 0.500000 | 0.000000 | 0.285835 |
| 5 | NaN | (5, 5) | 0.555556 | 0.642857 | 0.231481 | 0.397691 |
| 6 | NaN | (6, 5) | 0.555556 | 0.642857 | 0.231481 | 0.397691 |
| 7 | NaN | (7, 3) | 0.333333 | 0.600000 | 0.388889 | 0.195862 |
| 8 | NaN | (8, 2) | 0.222222 | 0.428571 | 0.222222 | 0.048075 |
| 9 | NaN | (9, 1) | 0.111111 | 0.310345 | 0.000000 | 0.011164 |
Summary#
Social network analysis provides a range of measures to depict the importance of a node.
The interpretation of each measure depends on the particular context in which it’s applied.
Similar to measures of network connectivity, these node importance measures could also be further enrichsed by considering direction, weight, and temporality. Please consult additional resources if interested.